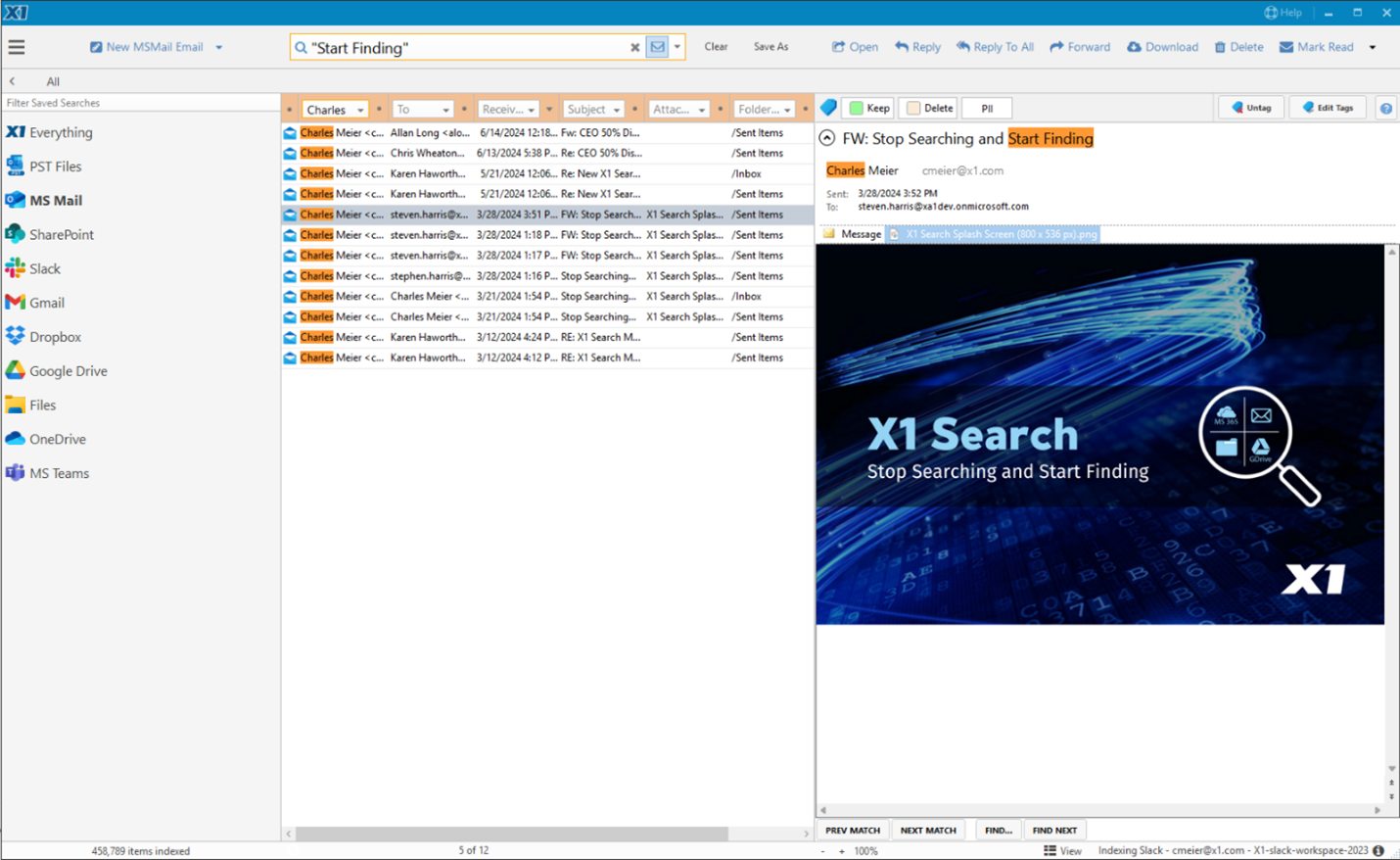
Enterprise search has long been a pain point for organizations—fragmented data, slow retrieval, and outdated architectures have left businesses struggling to find information efficiently, resulting in millions of hours of lost productivity. But with the release of X1 Search Version 10, a new era has arrived—one that redefines how business professionals search, discover, and act on their information across cloud and endpoint ecosystems.
And the standout features? Full integration with Slack, enhanced support for Microsoft 365, support for Gmail and Google Drive and numerous other cloud data sources, as well as improvements to our enterprise-grade speed and scalability! With version 10, you can now search Slack in tandem with your email, files, and your Microsoft 365 data sources, including Teams.
Slack and Teams have become the modern enterprise’s water cooler and meeting room rolled into one. It is where you and your colleagues have critical conversations, exchange files, and document decisions. But until now, most enterprise search tools could not index Slack effectively, let alone allow unified searching across Slack and email.
X1 Search 10 changes the game by uniquely enabling real-time search across Slack messages, channels, and attachments alongside your Outlook, M365, Google Workspace, files, and more—all in a single interface. This allows business professionals to instantly search all their key information and full context of communication threads, no matter where their conversations took place. Imagine searching, seeing, and acting on your relevant Slack chats, Teams chats, email threads, and related documents side by side, in seconds. No toggling between systems. No data blind spots. Just instant insight and supercharged productivity.
Speed, Scale, and Simplicity with Micro-Indexing What makes this lightning-fast and massively scalable experience possible is X1’s patented search and micro-indexing architecture. Unlike legacy systems that first require inefficient, time-consuming crawlers to collect, duplicate, and then transfer the data en masse into central repositories, which is a recipe for failure, X1 indexes data in-place. This means:
• No massive data movement • Real-time indexing at the source • Full maintenance of user permissions and access controls • Lightning-fast search response times—even across multi-terabyte datasets
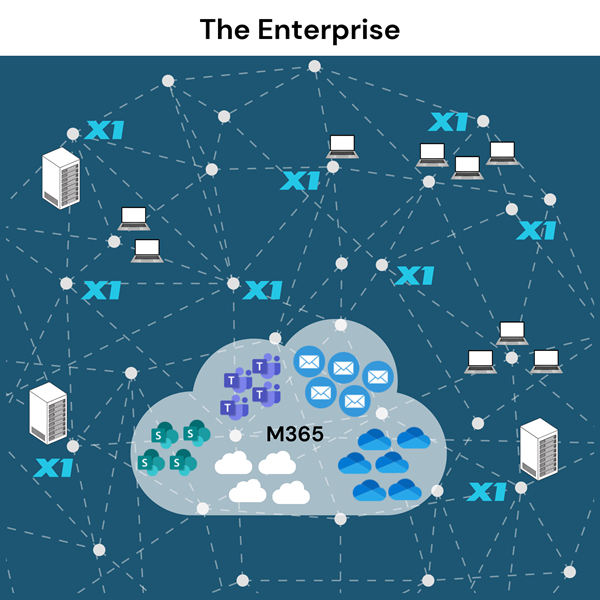
This distributed, index-in-place model is purpose-built for today’s data environment, where critical content lives across cloud platforms (Microsoft 365, OneDrive, SharePoint, Slack), endpoints, MS Exchange Servers, and file shares. With X1, organizations get a true federated view of enterprise content—without sacrificing speed, security, information governance, or user experience.
Legacy Enterprise Search Is Officially Obsolete Traditional enterprise search tools—built for centralized environments—are no match for the demands of the modern workplace. As data continues to fragment across cloud platforms, remote endpoints, and collaboration apps like Slack and Teams, the old Enterprise Content Management (ECM) model of copy and migration to centralized indexing is completely untenable in terms of the laws of physics as well as creating significant security and governance risks.
X1 Search leapfrogs past those outdated architectures. With native support for Slack, robust Microsoft 365 integration, and enterprise-grade security and scalability, X1 enables rapid search and collection across the full digital workplace.
No more hours of lost productivity per week. Just real-time, precise search across your enterprise data—wherever it lives.
Are you tired of wasting hours each week fruitlessly searching across emails, documents, cloud services, and local drives? You’re not alone. Law firms and major enterprises are increasingly recognizing the inherent limitations of legacy enterprise search solutions and turning decisively toward X1 Search.
X1 Search delivers a revolutionary user-based search experience that dramatically boosts productivity. Demand for X1 Search has skyrocketed this year—one major federal agency is expanding from 20,000 to over 40,000 licenses to equip every employee. Nearly half of AMLAW 100 firms now deploy or are actively considering X1. Why this rapid shift?
Traditional enterprise search solutions are fundamentally broken in today’s hybrid-cloud enterprise landscape. They rely heavily on outdated architectures that require mass data duplication and centralization—approaches rendered obsolete by remote work and distributed platforms such as Microsoft 365 and Google Workspace. Specifically, traditional tools face:
Scalability Roadblocks: Centralizing terabytes of distributed unstructured data is now effectively impossible in the modern enterprise.
Incompatibility with Modern Platforms: Legacy systems struggle to integrate effectively with platforms like Microsoft 365 due to restrictive APIs and loss of security permissions when the data is copied and exported en masse.
Regulatory and Governance Challenges: Mass duplication of sensitive data violates critical data protection regulations and contradicts fundamental information governance principles. The GDPR specifically mandates data minimization, particularly when viable alternative technologies exist, as evaluated through a Data Privacy Impact Analysis (DPIA).
Employees in modern organizations effectively have two viable search options: the limited native Windows search or the robust, efficient capabilities of X1 Search. Microsoft Copilot itself recently highlighted X1 Search’s advantages:
“X1 Search offers advanced indexing, instant search-as-you-type capabilities, powerful filtering, keyword highlighting, and document/email previews, significantly surpassing standard Windows Search. Moreover, X1 seamlessly searches across emails, documents, cloud storage, archived data, and more—far beyond Windows Search capabilities.”
X1 Search introduces an entirely new, distributed search architecture uniquely suited to today’s enterprise environments: • Distributed Micro-Indexing: Patented technology ensures secure, permission-aligned indexing, granting employees immediate, secure access to authorized data only. • No Mass Data Duplication: Interact directly with original documents without unnecessary duplication, ensuring compliance and efficiency. • True Federated Search: Search instantly and iteratively across M365, Google Workspace, Slack, and local data sources within a single unified search field—a capability unmatched by any other solution.
The latest X1 Search transcends desktop limitations, instantly searching Microsoft Email, Teams, Slack, OneDrive, SharePoint, local files, and now Google Drive and Gmail, all from one intuitive interface. This empowers users to reclaim hours each day, dramatically boosting productivity.
X1 Search’s intuitive design has won over 500,000 loyal users worldwide. As Max Underwood, from a top defense contracting firm, puts it:
“X1 Search is my go-to, must-have application. Nothing matches its speed and accuracy in helping me find precisely what I need, exactly when I need it.”
Stop Searching. Start Finding. Traditional search solutions are holding your business back. It’s time to break free and discover why top law firms and enterprises are standardizing on X1 Search.
Take the next step today: • Individual users: Purchase directly from our website. • Enterprise licenses: Contact us at sales@x1.com to start the conversation. Learn more at www.x1.com/solutions/x1-search/ and join the growing ranks of productive, satisfied X1 Search users today.
Microsoft reports 345 million paid users worldwide of its Microsoft 365 platform (“M365”), spanning over two million companies, with more than one million of them based in the United States. M365’s cloud-based data sources such as OneDrive, Outlook mail, Teams and SharePoint online represent arguably the majority of ESI being produced in litigation going forward. However, M365 presents significant eDiscovery challenges and costs, requiring legal and eDiscovery professionals to be aware of the various methods to address this critical data source.
This article briefly addresses the benefits and challenges of each of the three main approaches to addressing eDiscovery and information governance in M365: 1) Utilizing Microsoft Purview; 2) Outsourced Services; or 3) Relying on a 3rd Party Purpose-build eDiscovery Solution.
Microsoft Purview Microsoft Purview is the built-in M365 eDiscovery tool. It comes in different licensing tiers, the highest and most useful being Premium, or also known as E5 licenses. A key benefit of utilizing Purview Premium is that it’s integrated with M365, which is obviously convenient for workflow and also budgeting. Purview features a good legal hold process that allows the application of legal holds in place for key M365 data sources.
There is also a good consultant ecosystem to provide training and add-on services, which are often needed to address the larger projects at extra cost. And a premium license provides other functionalities unrelated to eDiscovery such as data analytics for business as well as a lot of security functions.
As far as the challenges of MS Purview Premium that we hear from users, a common complaint is that it can be very expensive, with licenses costing about $600 per employee annually. For large cases, licenses for several thousand custodians run in the millions of dollars and well into the tens of millions when you are dealing with a company with about 40,000 employees.
But the biggest complaint that we hear is that it’s not suited for large cases, M365 is built for user productivity, and the shared architecture is designed to support hundreds of millions of global users with normal individual workloads. eDiscovery and information governance projects are very large and aberrant workloads, so the system is designed to throttle large data throughputs. For instance, when you start a case in Purview, a separate and new index is created to allow eDiscovery and compliance searches in Purview, but there is a 2 GB hourly limit when creating this index — according to Microsoft’s own documentation — which limits your ability to address larger cases in a timely manner. There are many documented concerns about the accuracy and transparency of search results and data exports, especially as cases get bigger and there’s more custodians with higher volumes. Also, large attachments over 150 mb are not being a supported, as well as many filetypes such as engineering files like CAD drawings. MS only supports 50 file types, while the right eDiscovery software will support over 500.
These search accuracy and throughput limitations were called out by a Special Master Phillip Favro in the case of Deal Genius, LLC v. O2COOL, LLC, No. 21-C-2046, 2022 WL 17418933, at *1–2 (N.D. Ill. Oct. 24, 2022), and further expounded upon by Favro is his recent technical whitepaper:
“Purview eDiscovery does not provide the advanced features offered by a full service e-discovery platform needed to support discovery efforts in complex cases such as multidistrict litigation and class actions or regulatory investigations like Hart-Scott-Rodino Second Requests. Even small lawsuits that involve high volumes of ESI can present difficulties for organizations that wish to manage much of their discovery process with Purview eDiscovery. Responding parties that rely on Purview eDiscovery may not be able to perform a comprehensive search to reasonably identify relevant information. Responding parties who wish to incorporate Purview eDiscovery functionality into their discovery workflows must understand its search limitations and take steps to address them so they can establish the defensibility of their discovery process.” “Microsoft Purview eDiscovery: Key Features and Limitations,” Practical Law (July 2024).
Finally, Purview only addresses data within 365. It’s not going to address data sources such as Slack, or on-premises sources including laptops, fileshares, even on prem exchange or on-Prem SharePoint.
Outsourced Services The second approach to addressing M365 for eDiscovery is to retain an outsourced service provider. There are well over 100 consulting firms that perform such services, and the main benefit is that the right consultants can get the job done. The consultants know how to export M365 data into a standard eDiscovery workflow, are very good at project management, and are well-versed with working with attorneys and their litigation deadlines. For companies that are smaller without the internal resources or expertise or have backlogs, this can be a good approach.
The main drawback is that it can be very expensive, because often times what we generally see is the service providers parachute in and run very basic scripts to conduct a mass data export from M365. After that, it defaults to a traditional eDiscovery workflow with processing tools, a lot of manual services, and then an upload to a standard review platform. This reactive approach results in a high amount of expensive data overcollection. Additionally, outsourced service providers typically require very high level, super-admin privileges in order to run their bulk data download scripts, which can be a significant concern from a security standpoint. These privileges can be delegated sometimes without the company’s knowledge, so it is important to be aware of and audit the privileges that are being granted.
Also, we have seen that for large eDiscovery collection projects in Europe, EU based companies are required to perform a data protection impact analysis (DPIA), and mass bulk collections involving copying of all the employees’ emails and other sensitive files and taking that data offsite are frowned upon by privacy auditors. That approach runs afoul of the GDPR’s proportionality and data minimalization requirements.
Third Party eDiscovery Software Solution And finally, a third approach is utilizing a non-Microsoft eDiscovery solution that’s purpose- built to conduct eDiscovery, including by connecting to M365. A benefit of this approach is that the right solution can scale for larger data sets. This is particularly important for information governance projects such as data compliance audits. The good solutions will not require expensive Premium Purview licensing for every custodian and will enable you to employ it as an established and repeatable process. It can also address the indexing throughput and completeness challenges in Purview. And finally, a platform like this should be able to support data outside of M365 such as on-premises sources or data such as Slack.
One of the challenges of an in-house system is that internal IT resources or tech savvy paralegals are needed to run the process. Some technology platforms still require you to have the most expensive Purview Premium licensing to support essential functionality, such as collection of hyper-linked documents, and other key features. Further, many of these vendors are simply providing repurposed email archiving platforms, which function by a mass copy and transfer of all the organization’s data in M365. This poses significant logistical challenges in terms of scalability, not to mention unnecessary cost. M365 does not easily allow for the mass data download, which can lead to errors and data corruption, as in the recent case of FTC v. Match Group, No. 3:19-CV-2281-K, 2025 WL 46024, at *4 (N.D. Tex. Jan. 7, 2025) where MS Purview exports to an email archival system failed, resulting in court imposed discovery sanctions. So, if the solution does not allow for index in place functionality, but a bulk download, copy and data transfer, then there can be significant challenges with that approach.
The X1 Enterprise platform for 365 and on-premises sources takes a unique approach with a micro indexing architecture so that each data source and each custodian is associated with their own index. This enables a true index in place keep capability for targeted search and analytics at the point of collection, which enables the bypassing of most of the M365 throttling issues so that hundreds of custodians can be addressed in hours, not weeks. Our customers have successfully addressed matters involving thousands of custodians and upwards of 80 terabytes of M365 data that was indexed in a very short period of time. X1 Enterprise does not require Purview Premium licensing to address all the required functionality, such as the search and collection of hyperlinked files, archived email, inactive mailboxes, as well as many other detailed requirements.
Simply put, we believe X1 Enterprise is the best solution available to address M365 data for eDiscovery and information governance requirements.
Ready to Learn More? For companies navigating complex information governance and eDiscovery requirements, including those involving M365, organizations that rely on the X1 Enterprise Platform not only reduce costs and save valuable time but also gain a strategic advantage in managing their eDiscovery and information governance needs. For a demonstration of the X1 Enterprise Platform, contact us at sales@x1.com. For more details on this innovative solution, please visit www.x1.com/solutions/x1-enterprise-platform.
As legal and compliance teams grapple with exponential data growth, the need for faster, more efficient eDiscovery has never been greater. One key trend emerging from the 2025 State of Industry Report by eDiscovery Today is the growing demand for in-place indexing, with 15.5% of respondents citing it as a critical priority. But achieving true ‘index-in-place’ without bulk data transfers or excessive infrastructure costs—requires a fundamentally different architecture: distributed micro-indexing.
Unlike traditional eDiscovery tools that rely on centralized crawling and bulk data transfers, X1 Enterprise’s distributed micro-indexing architecture allows organizations to search, analyze, and collect data directly at the source—without moving vast amounts of information to a separate processing environment. This means faster insights, lower costs, and reduced security risks.
However, with this capability being highly valued, many vendors have parroted this messaging but have offerings that do not qualify as true index-in-place. Unlike traditional enterprise search or eDiscovery platforms that rely on centralized indexing (e.g., crawling, copying, and transferring all the data into a single repository), X1’s micro-indexing distributes the workload. It creates small, efficient indexes at the data source—whether a user’s laptop, email server, or a cloud source such as Microsoft 365 —and unifies search results on-demand. Transferring data in bulk to a central appliance or server farm via a crawling agent or Robocopy function does not qualify. A true index-in-place using distributed micro-indexes uniquely enables scalability, targeted collection and minimizes security and data governance risks in eDiscovery and information governance matters.
Earlier this year, a Fortune 500 company faced a massive eDiscovery and GDPR compliance challenge: indexing and searching over 70 terabytes of data across Microsoft 365and on-premises sources—all without disrupting operations. With X1 Enterprise, they accomplished this in just a few weeks—a feat impossible with traditional solutions that rely on slow, centralized processing.
X1’s unique approach is based upon distributed, micro-indexing search and collection capabilities. Below are the top ten benefits of this architecture tailored to eDiscovery and enterprise data governance and how it differs from alternative approaches.
Rapid, In-Place Data Identification: Legal teams can locate relevant documents across endpoints, cloud sources, and network drives instantly—without waiting for slow, centralized crawls. X1’s micro-indexing creates lightweight, decentralized indexes at the endpoint level (e.g., individual laptops, servers, or cloud accounts).
Real-Time Search Across Distributed Systems: Execute complex, Boolean-rich searches across terabytes of data in Microsoft 365, OneDrive, SharePoint, and beyond. X1 enables real-time, federated searches across up to hundreds of terabytes of multiple data sources (e.g., Microsoft 365, local drives, email archives) from a single interface, leveraging micro-indexes updated at the source.
Minimized Over-Collection Risks: X1’s Micro-indexing allows precise targeting of relevant data, minimizing the need to collect entire datasets for review. X1’s granular indexing supports instantaneous keyword searches and metadata filtering at the source.
Lower eDiscovery Costs: By eliminating the need to transfer and reprocess massive datasets, X1 slashes infrastructure and vendor fees. By indexing and searching data in-place (without moving it to a central repository), X1 nearly eliminates reliance on third-party processing tools and expensive manual services, with dramatically reduced time to review.
Optimized M365 eDiscovery Support: Avoids Microsoft Purview throttling, supports modern attachments, and enables cost-effective, high-speed data access. Each custodian is assigned an individual micro-index which enables X1 to achieve unmatched throughput, support modern attachments without premium licensing, address inactive mailboxes and more.
Massive Scalability: X1’s micro-indexing distributes the workload on a parallelized basis, allowing the index and searching of hundreds of terabytes of data in-place at speeds not seen before in the enterprise eDiscovery and information governance industry. Micro-indexes are updated incrementally and in real-time as new data comes in, rather than requiring batch copying and re-indexing of an entire corpus.
Support for Remote and Hybrid Workforces: X1’s endpoint indexing works seamlessly on distributed devices, ensuring data from remote employees or cloud platforms is readily accessible without requiring physical access.
Proactive Compliance & Risk Monitoring:Instantly identify PII, unencrypted sensitive files, and policy violations across the enterprise. With micro-indexes updated in real-time, X1 allows organizations to monitor for policy violations (e.g., PII exposure, unencrypted sensitive files) across endpoints, fileshares and M365 accounts instantly.
In-Place Remediation and Governance: As the data remains in place, remediation is effectively and accurately applied at scale. This contrasts to other “copy and move” processes that are merely working off-site with copies of your data, rendering effective remediation efforts extremely costly and burdensome, if not impossible.
Data Minimization and GDPR Compliance: X1’s capabilities directly map to the GDPR’s proportionality and data minimization requirements. In contrast, tools that require full disc imaging or bulk copy and transfer for basic eDiscovery collection are extremely problematic.
Conclusion For legal, compliance, and IT teams struggling with slow, expensive, and inefficient eDiscovery workflows, distributed micro-indexing is the future. X1 Enterprise’s unique in-place search ensures rapid results, reduced costs, and ironclad compliance—without moving or duplicating sensitive data. If your organization relies on Microsoft 365, remote workforces, or high-volume data environments, X1 provides the speed, scalability, and security you need.
The European Union (EU) General Data Protection Regulation (GDPR) requires that subject organizations ensure and demonstrate the protection of personal data under their control. GDPR Article 35 mandates that when implementing new data collection technologies or engaging in a major new project involving significant data collection, an organization must perform a Data Protection Impact Assessment (DPIA).
Recently, a Fortune 500 company with global operations successfully implemented X1 Enterprise to address their eDiscovery and information governance requirements throughout the EU region, involving both Microsoft 365 and on-premises data sources. This implementation required the vetting of X1 Enterprise by auditors and the internal Data Protection Officer through an extensive DPIA process, which X1 passed. The effort provides important industry insights into how our Fortune 500 customer leveraged X1’s unique, on-premises index-in-place and targeted search and collection features, as well as other data minimization capabilities, to meet the DPIA requirements.
The EU provides official guidance and a checklist for conducting an Article 35 DPIA. Among the key requirements is the consideration of the “current state of the technology” in the area and that the technology and collection processes have adequate “proportionality measures” in their collection capabilities to “ensure data minimalisation.” If processes and technology engage in overly broad data collection, the guidance suggests considering alternative technologies and methods.
The team at our Fortune 500 customer emphasized the following unique data minimalization capabilities and features of X1 Enterprise in their DPIA:
Index and Search Data In-Place. X1’s proprietary micro indexes enable the searching of data on laptops, file servers and Microsoft in-place so that only the potentially relevant data is collected for eDiscovery and data audits, which fulfills the GDPR’s proportionality requirements. In contrast, tools that require full disc imaging for basic eDiscovery collection are extremely problematic.
As the court said in In re Ford Motor Company, 345 F.3d 1315: “[E]xamination of a hard drive inevitably results in the production of massive amounts of irrelevant, and perhaps privileged, information…” Even worse, the collected data is then re-duplicated, often multiple times, by the examiner for archival purposes. And then the data is sent downstream for processing, which results in even more data duplication. Load files are created for further transfers, which are also duplicated. Notably, EU guidance for a DPIA analysis requires that organizations consider alternative data collection technologies and methods that have better “proportionality measures” to “ensure data minimalization.”
Blind Searches and User Enabled Review. Using X1 Enterprise, an administrator can run detailed system wide searches and receive a detailed search result report without having access or possession of the target data. Instead, the administrator can direct X1 to first present the search results to the end-user employee to review and apply tags to identify personal, relevant or non-personal data, thereby applying clear and detailed consent to the subsequent collection of any relevant information.
Segmentation of Data Regions vs. Creation of Central Data Lakes. X1 can be deployed behind an organizations’ firewall or their own private cloud instance in the EU. Each custodian/employee is associated with a single micro-index. This allows X1 to target searches to specific EU counties and segments of users. This contrasts to archiving or other eDiscovery tools that require bulk copying and intermingling of all user data to a central location, where additional back-up copies are made, all which directly run afoul of the data minimalization and proportionality requirements of the GDPR.
Delete Data In-Place. GDPR requires the deletion of non-compliant on demand. Purging data on managed archives does not suffice if other copies are on laptops, unmanaged servers and other unstructured sources. X1’s on-premises distributed architecture uniquely enables the systematic deleting of data in place.
Platform to Enforce GDPR and Privacy Policies. In addition to asserting X1 met the requirements and standards under GDPR mandated DPIA, our Fortune 500 customer noted as further justification in their DPIA that they also planned to utilize X1 Enterprise to enforce privacy policies and provisions under the GDPR. X1 Enterprise is an ideal platform to respond to Data Subject Access requests, proactively audit data sources to identify and remediate personal information, as well as systematically purge unneeded data that may contain personal information of EU data subjects.
Ready to Learn More? For companies navigating complex information governance and eDiscovery requirements, including those involving M365, the X1 Enterprise Platform ensures compliance while protecting privacy. By implementing X1 Enterprise, organizations can not only reduce costs and save valuable time but also gain a strategic advantage in managing their information governance needs. For a demonstration of the X1 Enterprise Platform, contact us at sales@x1.com. For more details on this innovative solution, please visit www.x1.com/solutions/x1-enterprise-platform.