By Chas Meier

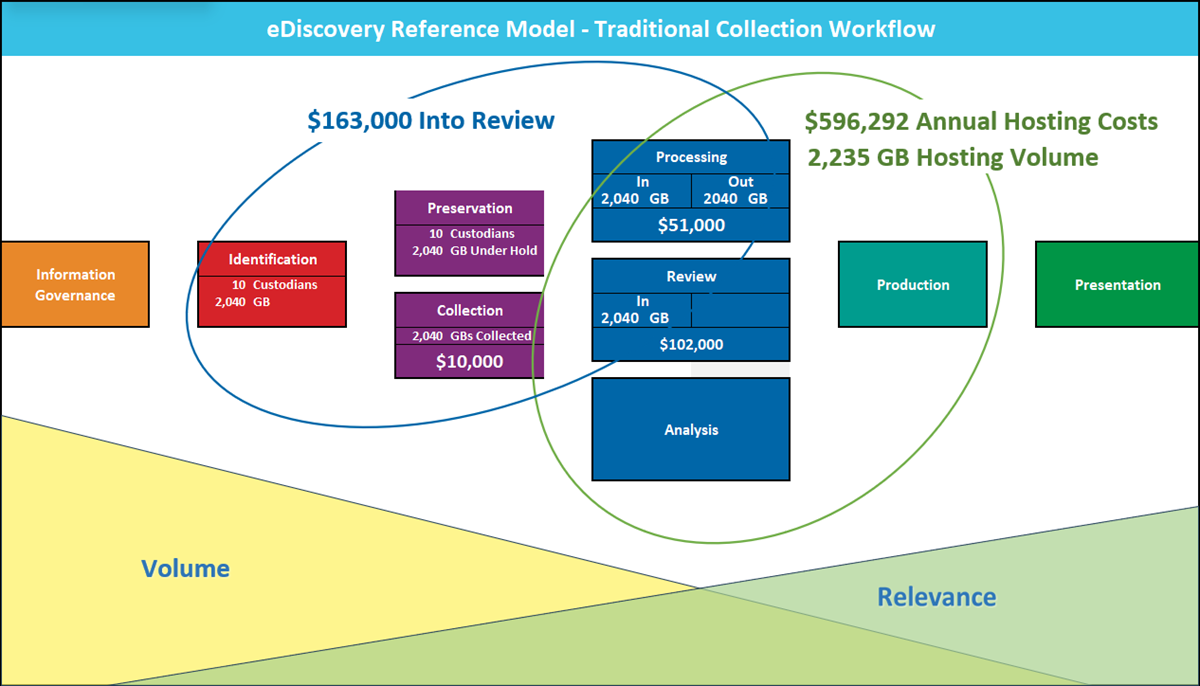
Users of Microsoft 365 for eDiscovery and Information Governance continue to encounter significant problems with low throughput and defensibility. Many customers report to us that Purview eDiscovery Premium’s documented limitations, including a 2GB per hour indexing limit, prevent them from using the platform to handle anything other than small matters. A routine eDiscovery matter involving one hundred custodians each with about 10GB of M365 data typically requires several weeks to complete with MS Purview Premium. This is a non-starter for legal teams who are up against pressing litigation timelines.
It is important to understand that because M365 is built on a large-scale multi-tenancy SaaS architecture, such challenges are a feature, not a bug of the system. Multi-tenancy is an architecture where shared computing resources are apportioned across large numbers of users. This architecture enables Microsoft to provide the service at a lower cost since computing services are shared.
However, multi-tenant architecture enables scale (in terms of multitudes of users) and efficiency through uniformity. These architectures are not designed for outlier workloads like eDiscovery that routinely require intensive surges in computing resources to collect, process and search terabytes of data. In fact, multi-tenancy cloud architects would identify eDiscovery workloads as a “noisy neighbor” that threatens the overall performance and user experience of the system, and thus must be managed through quality-of-service mechanisms like throttling and time-outs.
I think of multi-tenant architectures like the business model utilized by a gym. The gym has more and better equipment than I have at home, which is attractive so many will join through a membership. The gym has a fixed amount of square footage and equipment which is more than any individual needs and is sufficient to support those that show up, occasionally having to coordinate access to the equipment but manageable. However, what if a small group showed up at the gym every day for most of the day and hogged the equipment? What if more people showed up, became frustrated, and dissatisfied? Gym management would be forced to act to ensure fair access to the equipment.
Throughout my career as an eDiscovery service provider, we made large investments in infrastructure and capacity to the point of overkill to equip ourselves to service a client’s need to address high volumes of data in short timelines without impacting their business-as-usual activities. We were like the fire department for big unstructured data needs.
A huge differentiator in X1’s approach is to divide and conquer large scale projects by leveraging the cumulative power of a decentralized computing orchestrated through a unified management, search, and collection console. Think of this like deploying a fire suppression system proactively before the fire.
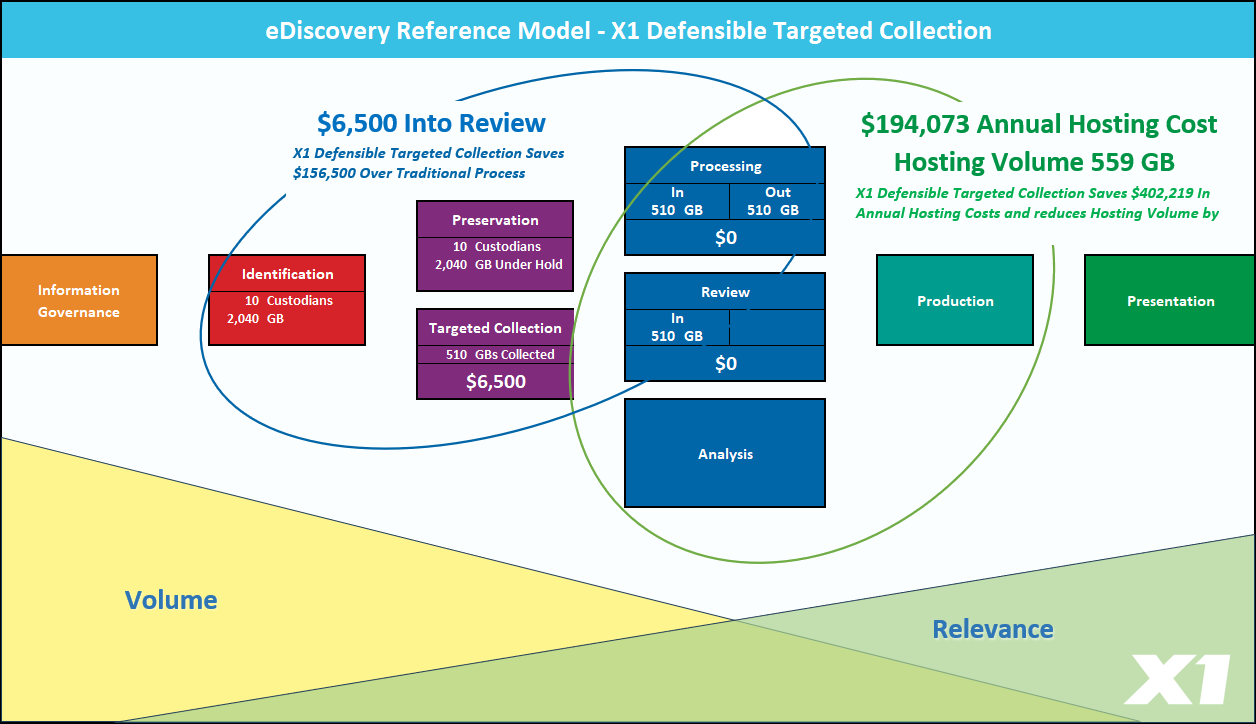
Last year, X1 introduced M365 data connectors into our X1 Enterprise platform to satisfy a critical need for enterprises to conduct cost-efficient yet highly scalable eDiscovery search and collection of M365 data. The response has been tremendous, with X1 seeing record demand in large part, due to the architectural limitations and deficiencies noted above.
X1 Enterprise Collect provides users the unique ability to index and search M365 data in-place and then collect in a targeted and iterative manner. This at speeds and throughput far exceeding other tools, including Microsoft Purview Premium. X1 achieves such scalability through a decentralized custodian-based approach that does not rely on the M365 or Purview search Index, which has known issues with the number of file types supported, consistency of search results, and throughput. X1’s approach enables a very scalable, defensible, and robust data collection at speeds far exceeding that of M365 Purview and other approaches.
For a demonstration of the X1 Enterprise Collect Platform, contact us at sales@x1.com. For more details on this innovative solution, please visit www.x1.com/solutions/x1-enterprise-platform.