My previous post discussed the inability of any software provider to solve a critical need by delivering a truly scalable eDiscovery preservation and collection solution that can search across thousands of enterprise endpoints in a short period of time. In the absence of such a “holy grail” solution, eDiscovery collection remains dominated by either unsupervised custodian self-collection or manual services, driving up costs while increasing risk and disruption to business operations.
So today, we at X1 are excited to announce the release of X1 Distributed Discovery. X1 Distributed Discovery (X1DD) enables enterprises to quickly and easily search across up to tens of thousands of distributed endpoints and data servers from a central location. Legal and compliance teams can easily perform unified complex searches across both unstructured content and metadata, obtaining statistical insight into the data in minutes, and full results with completed collection in hours, instead of days or weeks. Built on our award-winning and patented X1 Search technology, X1DD is the first product to offer true and massively scalable distributed data discovery across an organization. X1DD replaces expensive, cumbersome and highly disruptive approaches to meet enterprise discovery, preservation, and collection needs.
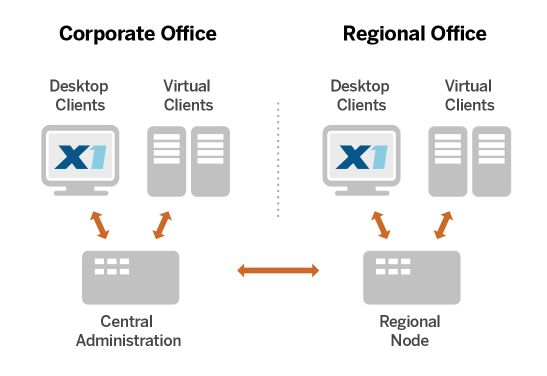
Enterprise eDiscovery collection remains a significant pain point, subjecting organizations to both substantial cost and risk. X1DD addresses this challenge by starting to show results from distributed data across global enterprises within minutes instead of today’s standard of weeks, and even months. This game-changing capability vastly reduces costs while greatly mitigating risk and disruption to operations.
Targeted and iterative end point search is a quantum leap in early data assessment, which is critical to legal counsel at the outset of any legal matter. However, under today’s industry standard, the legal team is typically kept in the dark for weeks, if not months, as the manual identification and collection process of distributed, unstructured data runs its expensive and inefficient course. To illustrate the power and capabilities of X1DD, imagine being able to perform multiple detailed Boolean keyword phrase searches with metadata filters across the targeted end points of your global enterprise. The results start returning in minutes, with granular statistical data about the responsive documents and emails associated with specific custodians or groups of custodians.
Once the legal team is satisfied with a specific search string, after sufficient iteration, the data can then be collected by X1DD by simply hitting the “collect” button. The responsive data is “containerized” at each end point and automatically transmitted to a central location, where all data is seamlessly indexed and ready for further culling and first pass review. Importantly, all results are tied back to a specific custodian, with full chain of custody and preservation of all file metadata.
This effort described above — from iterative distributed search through collection, transmittal to a central location, and indexing of data from thousands of endpoints — can be accomplished in a single day. Using manual consulting services, the same project would require several weeks and hundreds of thousands of dollars in collection costs alone, not to mention significant disruption to business operations. Substantial costs associated with over-collection of data would mount as well.
X1DD operates on-demand where your data currently resides — on desktops, laptops, servers, or even the Cloud — without disruption to business operations and without requiring extensive or complex hardware configurations. Beyond enterprise eDiscovery and investigation functionality, organizations can offer employees the award-winning X1 Search, improving productivity while maintaining compliance.
X1DD will be featured in an April 19 webinar with eDiscovery expert Erik Laykin of Duff & Phelps. Watch a full briefing and technical demo of X1DD and find out for yourself why X1 Distributed Discovery is a game-changing solution. Or please contact us to arrange for a private demo.