
By John Patzakis and Chas Meier
As legal and compliance teams grapple with exponential data growth, the need for faster, more efficient eDiscovery has never been greater. One key trend emerging from the 2025 State of Industry Report by eDiscovery Today is the growing demand for in-place indexing, with 15.5% of respondents citing it as a critical priority. But achieving true ‘index-in-place’ without bulk data transfers or excessive infrastructure costs—requires a fundamentally different architecture: distributed micro-indexing.
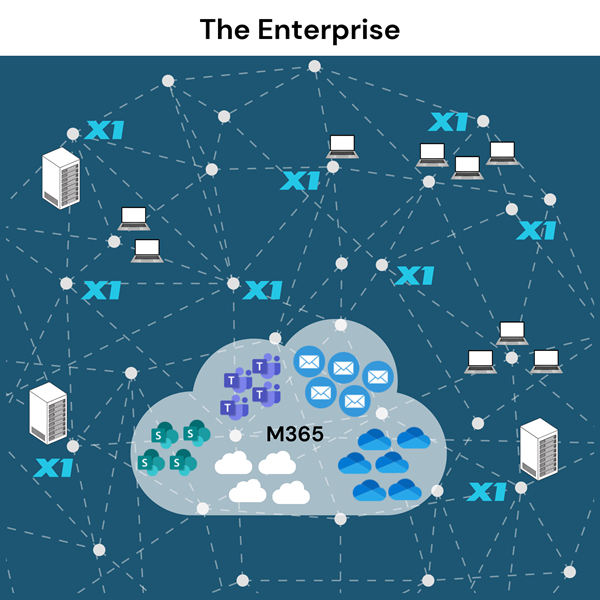
Unlike traditional eDiscovery tools that rely on centralized crawling and bulk data transfers, X1 Enterprise’s distributed micro-indexing architecture allows organizations to search, analyze, and collect data directly at the source—without moving vast amounts of information to a separate processing environment. This means faster insights, lower costs, and reduced security risks.
However, with this capability being highly valued, many vendors have parroted this messaging but have offerings that do not qualify as true index-in-place. Unlike traditional enterprise search or eDiscovery platforms that rely on centralized indexing (e.g., crawling, copying, and transferring all the data into a single repository), X1’s micro-indexing distributes the workload. It creates small, efficient indexes at the data source—whether a user’s laptop, email server, or a cloud source such as Microsoft 365 —and unifies search results on-demand. Transferring data in bulk to a central appliance or server farm via a crawling agent or Robocopy function does not qualify. A true index-in-place using distributed micro-indexes uniquely enables scalability, targeted collection and minimizes security and data governance risks in eDiscovery and information governance matters.
Earlier this year, a Fortune 500 company faced a massive eDiscovery and GDPR compliance challenge: indexing and searching over 70 terabytes of data across Microsoft 365 and on-premises sources—all without disrupting operations. With X1 Enterprise, they accomplished this in just a few weeks—a feat impossible with traditional solutions that rely on slow, centralized processing.
X1’s unique approach is based upon distributed, micro-indexing search and collection capabilities. Below are the top ten benefits of this architecture tailored to eDiscovery and enterprise data governance and how it differs from alternative approaches.
- Rapid, In-Place Data Identification: Legal teams can locate relevant documents across endpoints, cloud sources, and network drives instantly—without waiting for slow, centralized crawls. X1’s micro-indexing creates lightweight, decentralized indexes at the endpoint level (e.g., individual laptops, servers, or cloud accounts).
- Real-Time Search Across Distributed Systems: Execute complex, Boolean-rich searches across terabytes of data in Microsoft 365, OneDrive, SharePoint, and beyond. X1 enables real-time, federated searches across up to hundreds of terabytes of multiple data sources (e.g., Microsoft 365, local drives, email archives) from a single interface, leveraging micro-indexes updated at the source.
- Minimized Over-Collection Risks: X1’s Micro-indexing allows precise targeting of relevant data, minimizing the need to collect entire datasets for review. X1’s granular indexing supports instantaneous keyword searches and metadata filtering at the source.
- Lower eDiscovery Costs: By eliminating the need to transfer and reprocess massive datasets, X1 slashes infrastructure and vendor fees. By indexing and searching data in-place (without moving it to a central repository), X1 nearly eliminates reliance on third-party processing tools and expensive manual services, with dramatically reduced time to review.
- Optimized M365 eDiscovery Support: Avoids Microsoft Purview throttling, supports modern attachments, and enables cost-effective, high-speed data access. Each custodian is assigned an individual micro-index which enables X1 to achieve unmatched throughput, support modern attachments without premium licensing, address inactive mailboxes and more.
- Massive Scalability: X1’s micro-indexing distributes the workload on a parallelized basis, allowing the index and searching of hundreds of terabytes of data in-place at speeds not seen before in the enterprise eDiscovery and information governance industry. Micro-indexes are updated incrementally and in real-time as new data comes in, rather than requiring batch copying and re-indexing of an entire corpus.
- Support for Remote and Hybrid Workforces: X1’s endpoint indexing works seamlessly on distributed devices, ensuring data from remote employees or cloud platforms is readily accessible without requiring physical access.
- Proactive Compliance & Risk Monitoring: Instantly identify PII, unencrypted sensitive files, and policy violations across the enterprise. With micro-indexes updated in real-time, X1 allows organizations to monitor for policy violations (e.g., PII exposure, unencrypted sensitive files) across endpoints, fileshares and M365 accounts instantly.
- In-Place Remediation and Governance: As the data remains in place, remediation is effectively and accurately applied at scale. This contrasts to other “copy and move” processes that are merely working off-site with copies of your data, rendering effective remediation efforts extremely costly and burdensome, if not impossible.
- Data Minimization and GDPR Compliance: X1’s capabilities directly map to the GDPR’s proportionality and data minimization requirements. In contrast, tools that require full disc imaging or bulk copy and transfer for basic eDiscovery collection are extremely problematic.
Conclusion
For legal, compliance, and IT teams struggling with slow, expensive, and inefficient eDiscovery workflows, distributed micro-indexing is the future. X1 Enterprise’s unique in-place search ensures rapid results, reduced costs, and ironclad compliance—without moving or duplicating sensitive data. If your organization relies on Microsoft 365, remote workforces, or high-volume data environments, X1 provides the speed, scalability, and security you need.
Ready to Learn More?
Discover how X1 Enterprise can revolutionize your eDiscovery and compliance strategy. Schedule a demo today at sales@x1.com or visit www.x1.com/solutions/x1-enterprise-platform.





