
By John Patzakis and Chas Meier

When employees leave an organization, they often leave behind a significant amount of valuable information. This poses major information governance challenges, as companies must decide how to manage litigation holds and retain essential data assets.
A common response to this challenge is to retain departed employees’ laptops, hard drives, or keep their Microsoft 365 or Google Workspace accounts active. However, this approach is both expensive and inefficient. Another often-used method is creating a full disk image of the laptop for archiving. While this preserves data, it is a slow and cumbersome process that can require vast amounts of storage, sometimes reaching petabytes, which becomes both costly and unwieldy. Neither approach offers the ability to gain insights from the data, nor do they allow for intelligent and targeted data extraction, making it difficult to leverage these data assets effectively or comply with legal and regulatory requirements.
To address these challenges, X1 has developed a game-changing workflow utilizing our X1 Enterprise Platform, offering a streamlined and cost-effective solution. With our platform, organizations can process hundreds of laptops and Microsoft 365 accounts in a single day. Leveraging X1’s unique and patented in-place indexing technology, data extraction becomes highly targeted, allowing for efficient responses to litigation holds. This means that each litigation scenario can have a tailored search applied across all relevant data sources simultaneously, enabling precise data extraction.
For example, one company with over two dozen active litigation holds has employed X1’s solution, allowing them to save detailed keyword search routines crafted by their counsel. These searches can be quickly and programmatically applied not only to data on specific laptops but also to archived PSTs and associated Microsoft 365 accounts. Once the targeted data is extracted, the company repurposes the laptops for new employees, resulting in significant cost savings—estimated to be in the millions—and a reduction in storage requirements.
Beyond managing litigation holds, another core benefit of X1’s solution is its ability to extract key data assets from departed employees to retain within the company’s knowledge base. This capability is especially valuable for law firms, consulting firms, and organizations that rely heavily on high-end knowledge professionals. For instance, one law firm uses X1’s workflow to rapidly search large, archived PST files from departed attorneys to identify and separate key data related to ongoing matters. This ensures that crucial information remains accessible to the firm or is appropriately transferred to the attorney’s new firm. Additionally, vital legal and business insights from retained documents and emails are quickly mined and reviewed, enhancing the firm’s overall knowledge management.
Client Example:
• Overview: A major pharmaceutical retailer uses X1 within Relativity to perform 50 data collections weekly, covering both Mac and PC environments. The system allows them to repurpose laptops from departed employees within days instead of months, leading to substantial savings.
• Integration: The company eliminated the need for traditional eDiscovery tools to remediate laptops, opting instead for X1’s more efficient approach.
• Time and Cost Savings: This shift has saved the company millions by:
1. Reducing the reliance on costly traditional eDiscovery tools.
2. Minimizing the risk and cost associated with retaining unnecessary data.
3. Reintroducing millions of dollars’ worth of computer equipment back into circulation.
4. Completing these processes in one-tenth the time it would have traditionally taken, vastly improving operational efficiency.
Conclusion:
In today’s fast-paced and data-driven world, organizations face numerous challenges when it comes to managing and retaining data from departed employees. Traditional methods, such as retaining physical devices or creating full disk images, are not only costly and time-consuming but also fail to provide the flexibility and insight needed to effectively manage information assets. X1’s innovative solutions, particularly its patented in-place indexing technology, offer a modern, scalable, and efficient alternative. By enabling targeted data extraction, streamlining the process for litigation holds, and supporting knowledge retention, X1 empowers organizations to manage data governance with precision and agility.
For companies navigating complex data environments, especially those utilizing BYOD policies, X1 Enterprise Platform ensures compliance while protecting privacy. By implementing X1’s advanced platform, organizations can not only reduce costs and save valuable time but also gain a strategic advantage in managing their information governance needs. We invite you to explore how X1 can transform your data management processes and help you stay ahead in the ever-evolving digital landscape.


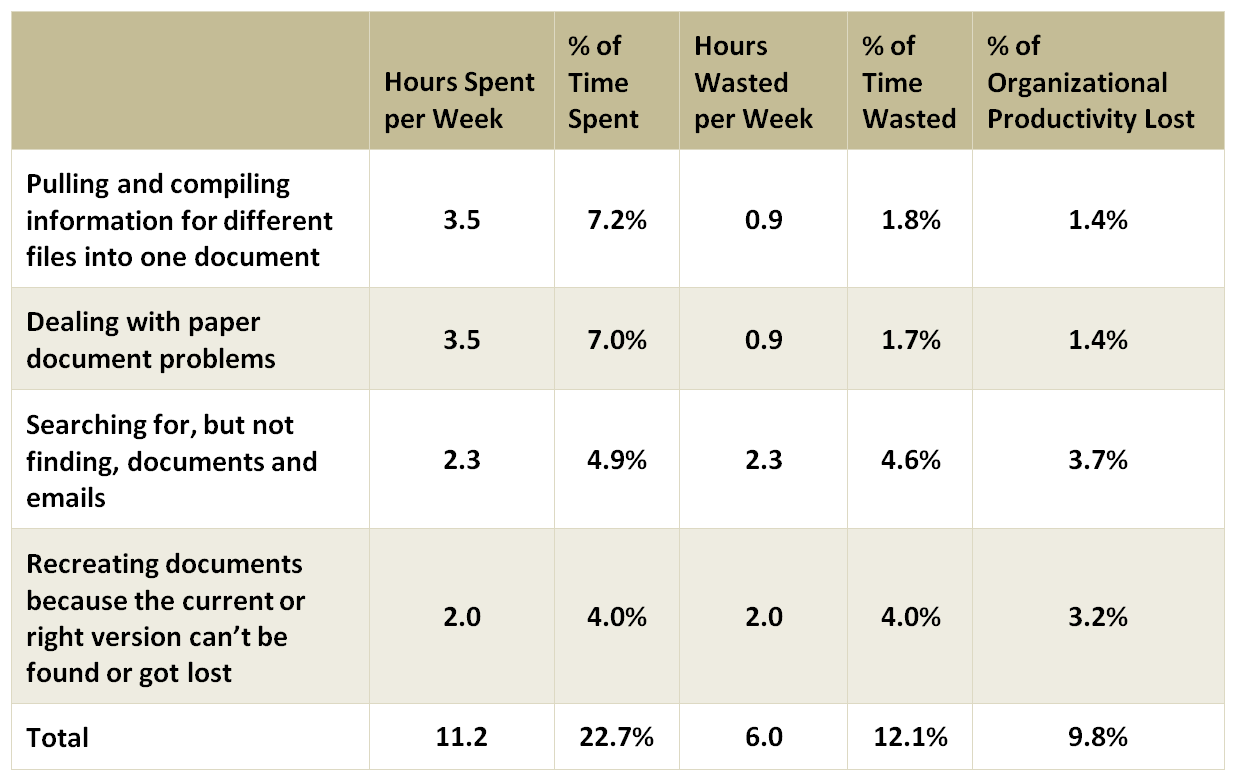 Source: IDC’s Information Worker Survey, June 2012
Source: IDC’s Information Worker Survey, June 2012
